Step 1: After deploying the appliance, connect to it via port 5480 and log in as the user admin.

2. Select Summary on the left side and click on Configure Appliance

3. Specify the information of the vCenter Server/PSC and authenticate yourself to it.
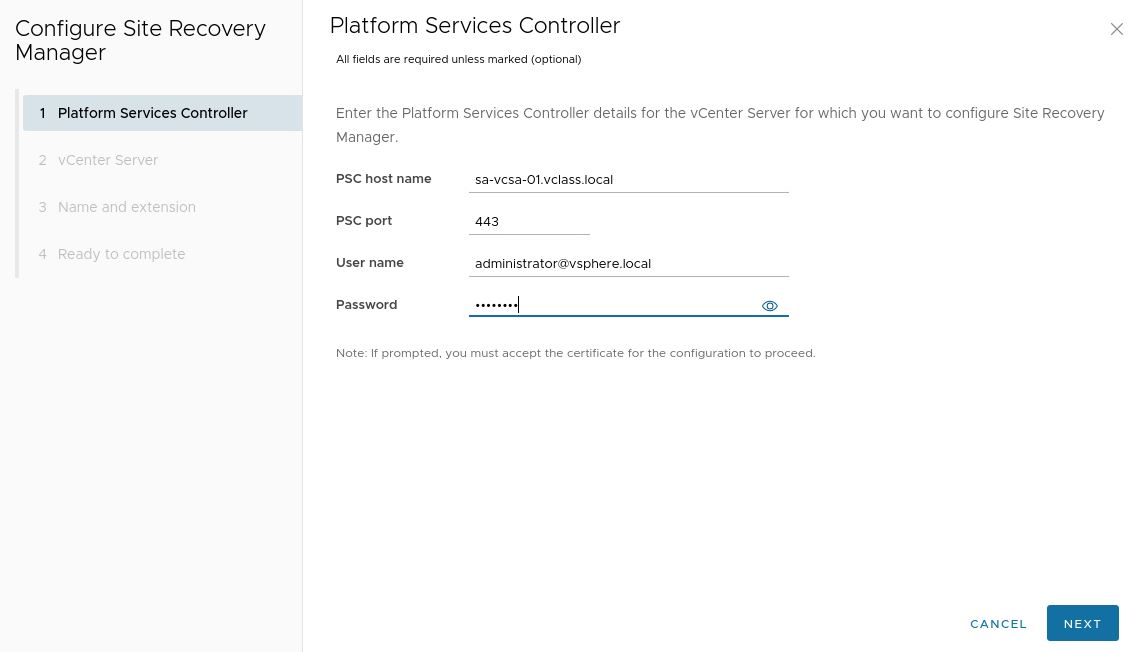

5. Specify the site name and provide email information

6. Verify your settings and click on Finish.

7. Connect to your vCenter Server via the vSphere Client.

9. Pair the two sites.
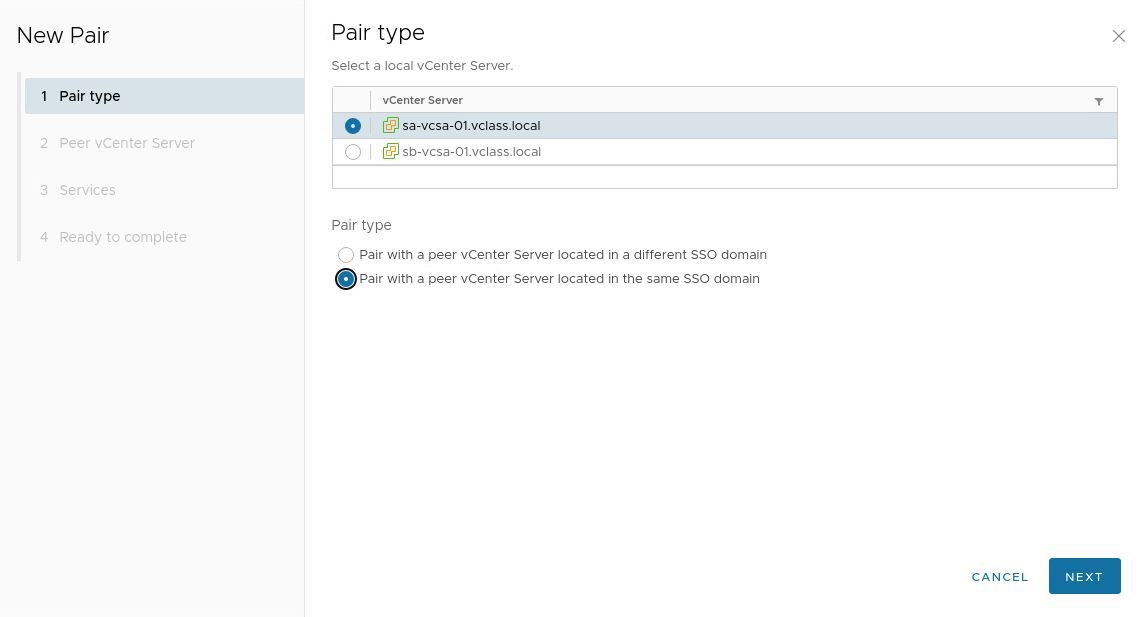
10. Select the other vCenter Server
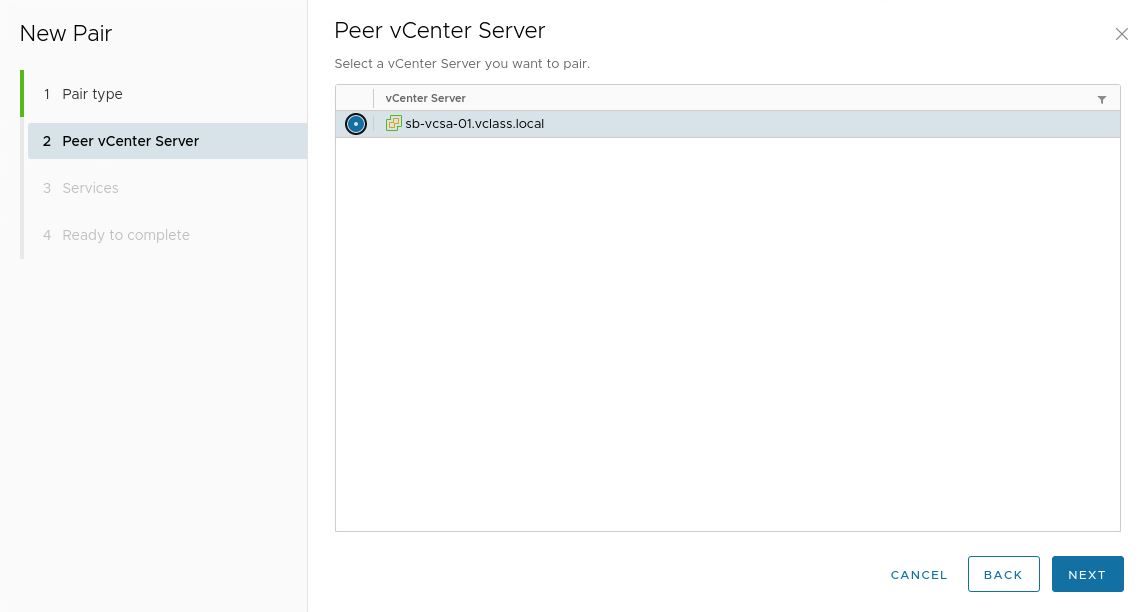
11. Review the services recognized and the pairing of the sites.
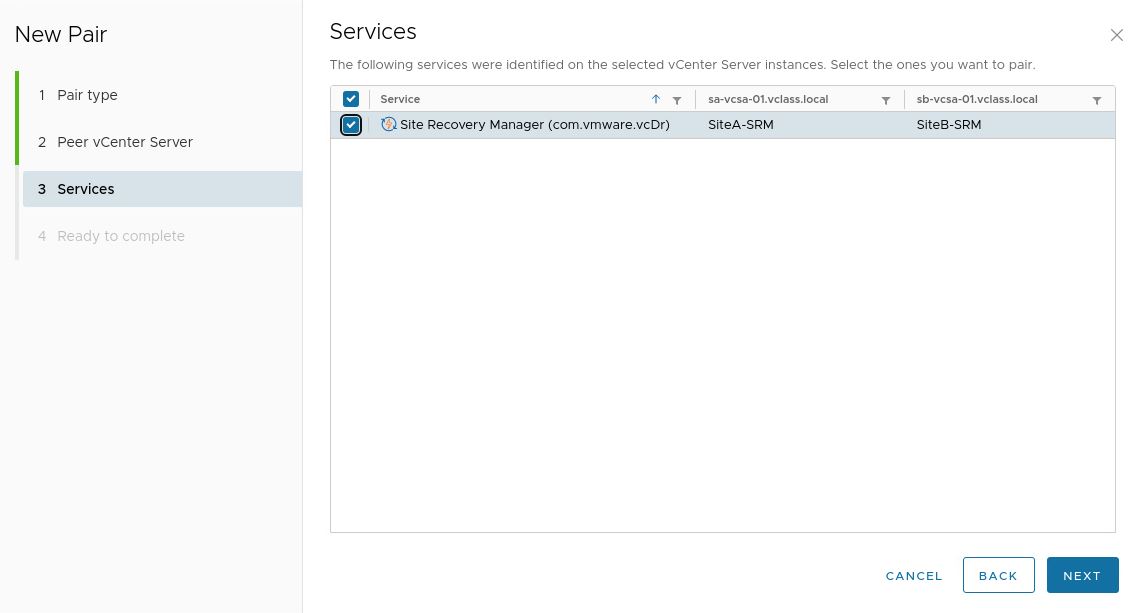
12. Click on Finish should everything look correct.
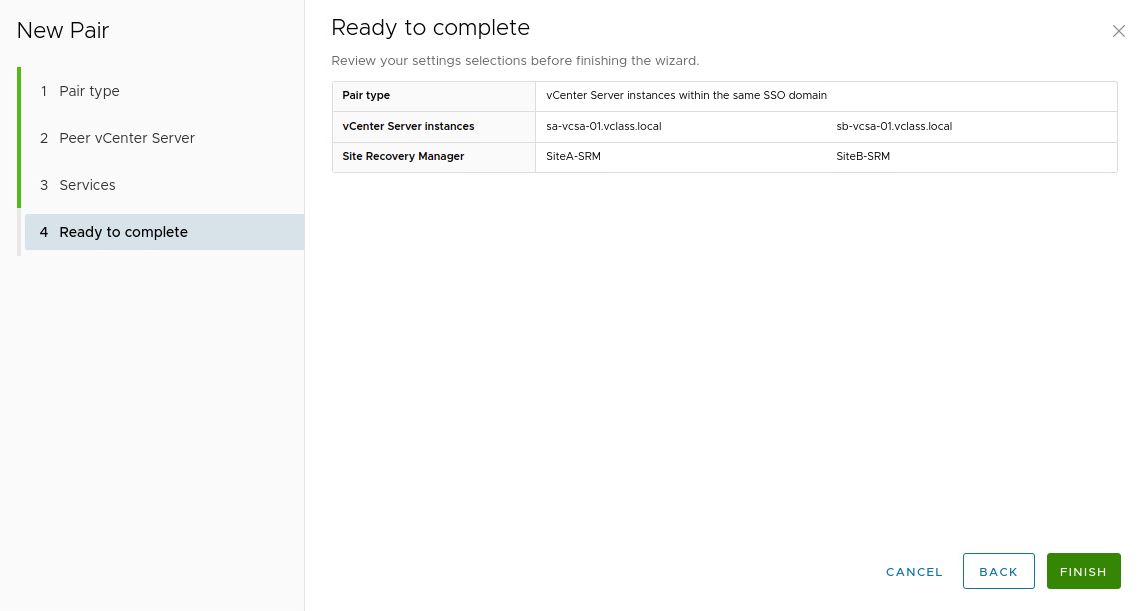
13. You shoud see the two vCenter Servers.

Final Note: What is next? Lots of things, inventory mappings, the deployment of the replication appliances, protection groups and recovery plans.